I just finished
an app engine site that plots some housing rentals in Ann Arbor on google maps (
source). I originally started working on it out of frustration that
housing maps doesn't support Ann Arbor. About half way through I realized
mapskrieg does, but by then I had already found an excuse to play around with some of app engine's latest features so I was happy to finish it up :) Even though it is hard coded to listings in Ann Arbor, it works based off a list of craigslist search urls, so it could be targeted anywhere.
The meat of the server is pretty simple:
class RefreshCron(webapp.RequestHandler):
"Cron job that refreshes listings for each housing URL"
def get(self):
import pickle
# fire off tasks for each url
for url in HOUSING_URLS:
taskqueue.add(
url="/task/craigsrss",
payload=pickle.dumps(url),
headers={"Content-Type": "application/octet-stream"})
self.redirect("/")
class CraigsRssTask(webapp.RequestHandler):
"""takes in a url to a craigslist rss feed, and grabs
each entry. for each one, fires off a DetailsTask to
get the detail of each listing."""
def post(self):
import pickle
url = pickle.loads(self.request.body) + "&format=rss"
listings = parseListings(fetchContent(url))
for listing in listings:
taskqueue.add(
url='/task/fetchdetails',
payload=pickle.dumps(listing),
headers={"Content-Type": "application/octet-stream"})
self.redirect("/")
class DetailsTask(webapp.RequestHandler):
"""Fetches details from one listing and stores the
full listing in the datastore. The listing is passed in the request
body as a pickled dictionary."""
def post(self):
import pickle
listing = pickle.loads(self.request.body)
url = listing["url"]
text = fetchContent(url)
address = extractAddr(text)
photos = extractPhotos(text)
lat,longit = parseGeocode(fetchContent(geocodeUrl(address)))
listingStored = ListingStore(
title=listing["title"],
url=url,
address=address,
photos=photos,
lat=lat,
longit=longit)
listingStored.put()
A cron job posts a task for each craigslist search url using the
experimental task queue feature. Each rss task parses the feed and some initial data about each listing, and then posts another task to gather the rest of the details from the listing url (including address and photo extraction, and geocoding of the address). What's really cool is this all fans out in parallel, which means a 100+ listings can be parsed and ready to go very quickly. With the addition of the task queue, I feel like app engine's request timeout has turned from a pesky limitation to a helpful reminder that if you are doing too much work in any single request handler, you are doing it wrong and should thing about how to break it down into smaller tasks that can be parallelized. Since firing off a task is almost as easy as calling a function, there's really no excuse not to.
The
development server does a really nice job with tasks. Instead of firing them all off automatically, you can view each task in an admin console and fire them off one at a time to make sure everything is working properly, and also verify the tasks that you expect to show up do.
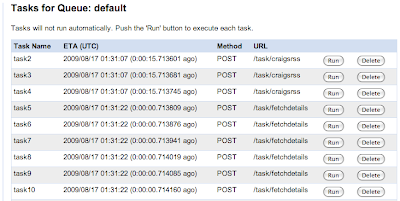
Unfortunately, you don't get the same interface once the app is running in production; it would be nice to have a way to see what tasks were pending, or at least flush them out in case a task is repeatedly barfing (as happened to me the first time I uploaded). Another feature I'd like to see was a way to have a handler notified when a queue empties out to facilitate multi-stage parallel processing. But overall I'm impressed with the task queue and look forward to it becoming a core feature (and available on the jvm).
